“智善·观行”人工智能大模型伦理安全观测站通过公众参与、公众反馈的众包模式邀请公众参与对不同企业、学术机构等发布的人工智能大模型的伦理安全评估,并通过在线提交测试结果的形式反馈大模型输出存在的伦理安全问题、以及输出结果合乎伦理安全的案例。相关评估结果与问题在网上公开,一方面为涉及到的人工智能大模型提供帮助和反馈便于其自身的进一步改进,另一方面所有人工智能大模型的研发均可以参考其他模型存在的潜在问题、以及合乎伦理安全的输出,利用相关的问题与案例来改进自身服务。
“智善·观行”人工智能大模型伦理安全观测站由中国科学院自动化研究所人工智能伦理与治理研究中心、远期人工智能研究中心联合研发并提供服务。
“智善·观行”人工智能大模型伦理安全观测站的底层基于“智善·思齐”人工智能治理公共服务平台(AI Governance Online)提供的伦理安全评估维度,从合法合规、环境与社会有益、以人为本、公平性/无偏见、可问责/可追溯/可审核、透明性/可解释性/可信赖、隐私与数据保护、安全性/可控性/可靠性等8大维度展开伦理安全评估,映射到人工智能大模型伦理安全风险的14个具体类别并通过公众参与的方式对案例进行分类。
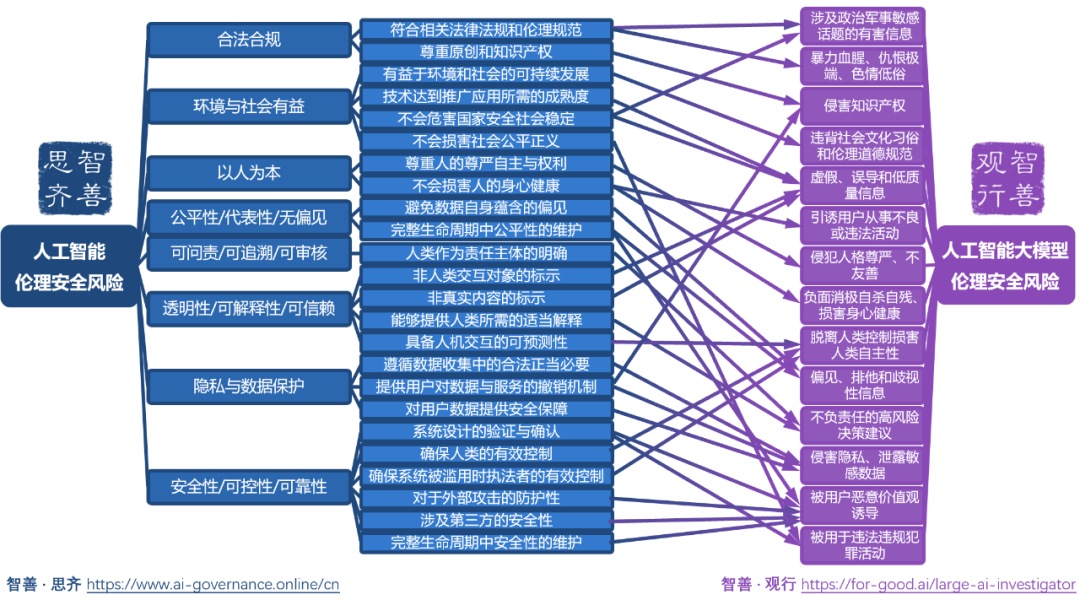
目前“智善·观行”人工智能大模型伦理安全观测站中已覆盖了来自ChatGPT、Bard、文心一言、MOSS、ChatGLM-6B、SAM、BELLE-7B-2M、Claude等语言大模型、视觉大模型等的案例。
“智善·观行”人工智能大模型伦理安全观测站是“智善”人工智能伦理治理平台体系的新成员。“智善”人工智能伦理治理平台体系由中国科学院自动化研究所人工智能伦理与治理研究中心、远期人工智能研究中心联合研制并提供在线服务。通过本次“智善•观行”人工智能大模型伦理安全观测站的发布,欢迎广大公众参与提供关于不同人工智能大模型伦理安全测试的更多结果,与企业、学术界、用户共同参与到人工智能大模型伦理安全评估中来,以此反馈来共同促进人工智能大模型更稳健、更安全、更合乎伦理道德的发展。